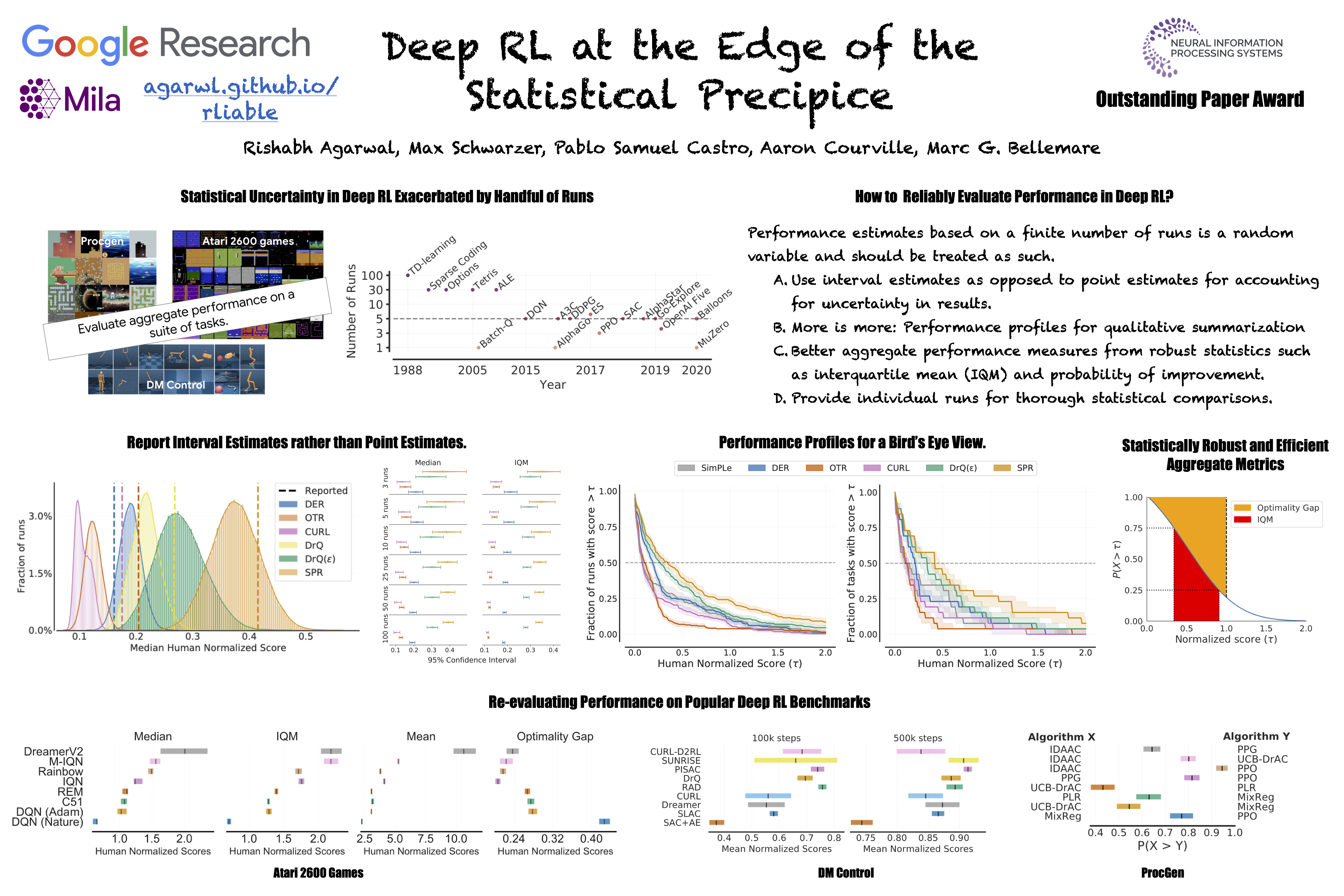
Our findings call for a change in how we evaluate performance in deep RL, for which we present a more rigorous evaluation methodology, accompanied with an open-source library rliable, to prevent unreliable results from stagnating the field.
Citing
To cite this paper, please use the following reference:
@article{agarwal2021deep,
title={Deep reinforcement learning at the edge of the statistical precipice},
author={Agarwal, Rishabh and Schwarzer, Max and Castro, Pablo Samuel and Courville, Aaron C and Bellemare, Marc},
journal={Advances in Neural Information Processing Systems},
volume={34},
year={2021}
}
Authors





For questions, please contact us at: rishabhagarwal@google.com.