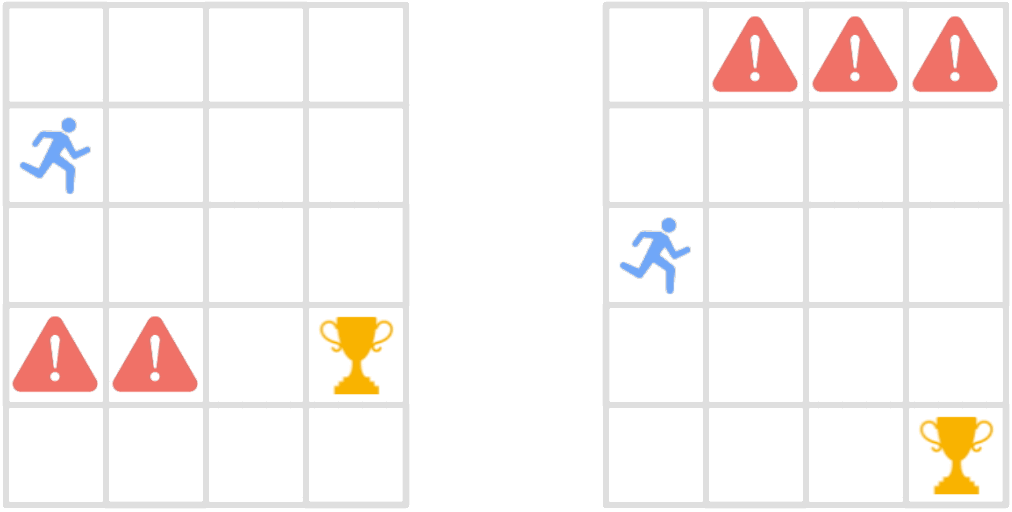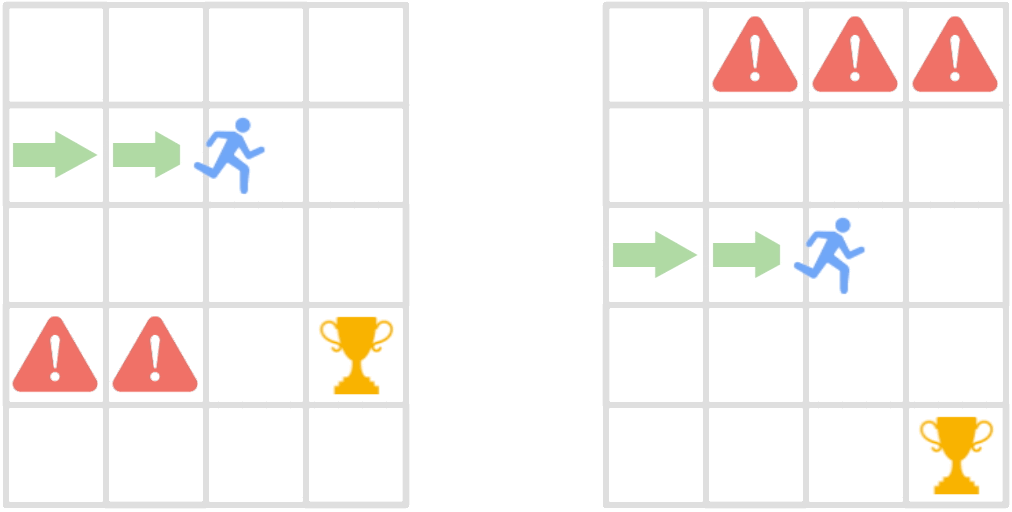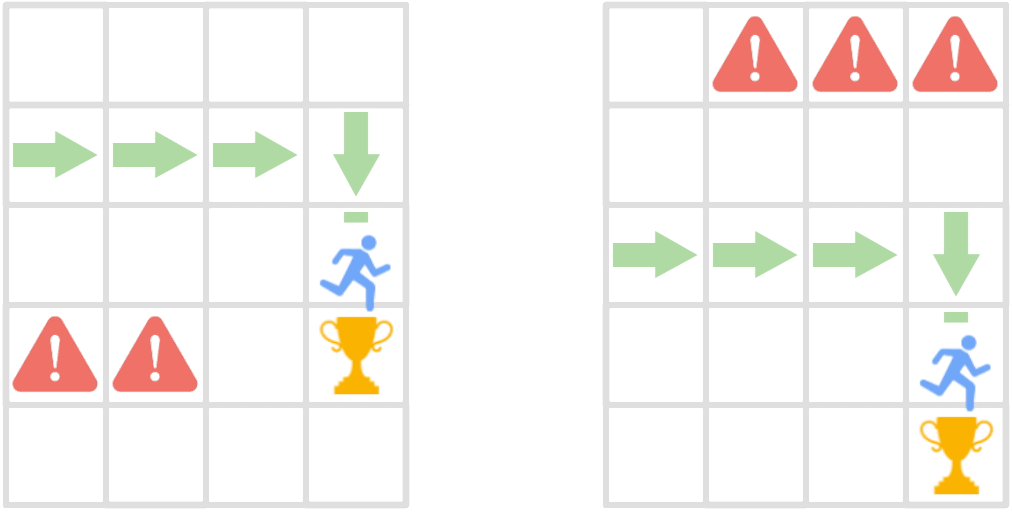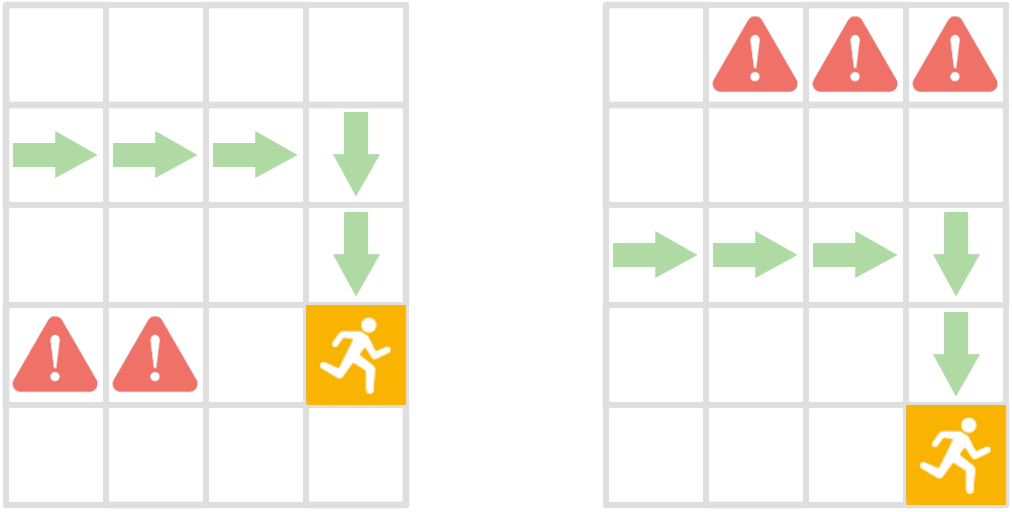
Reinforcement learning methods trained on few environments rarely learn policies that generalize to unseen environments. To improve generalization, we incorporate the inherent sequential structure in reinforcement learning into the representation learning process. This approach is orthogonal to recent approaches, which rarely exploit this structure explicitly. Specifically, we introduce a theoretically motivated policy similarity metric (PSM) for measuring behavioral similarity between states. PSM assigns high similarity to states for which the optimal policies in those states as well as in future states are similar. We also present a contrastive representation learning procedure to embed any state similarity metric, which we instantiate with PSM to obtain policy similarity embeddings (PSEs). We demonstrate that PSEs improve generalization on diverse benchmarks, including LQR with spurious correlations, a jumping task from pixels, and Distracting DM Control Suite.
Citing
To cite this paper, please use the following reference:
@inproceedings{agarwal2021pse,
title={Contrastive Behavioral Similarity Embeddings for Generalization in Reinforcement Learning},
author={Agarwal, Rishabh and Machado, Marlos C. and Castro, Pablo Samuel and Bellemare, Marc G.},
booktitle={International Conference on Learning Representations},
year={2021}
}
Authors




For questions, please contact us at: rishabhagarwal@google.com.