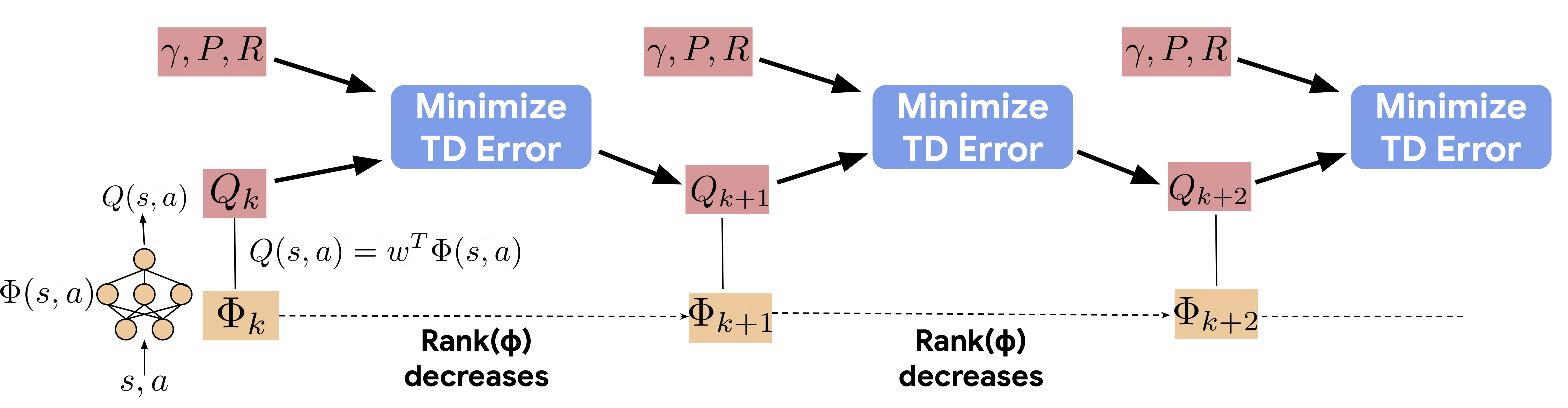
We identify an implicit under-parameterization phenomenon in value-based deep RL methods that use bootstrapping: when value functions, approximated using deep neural networks, are trained with gradient descent using iterated regression onto target values generated by previous instances of the value network, more gradient updates decrease the expressivity of the current value network. We characterize this loss of expressivity in terms of a drop in the rank of the learned value network features, and show that this corresponds to a drop in performance. We demonstrate this phenomenon on widely studies domains, including Atari and Gym benchmarks, in both offline and online RL settings. We formally analyze this phenomenon and show that it results from a pathological interaction between bootstrapping and gradient-based optimization. We further show that mitigating implicit under-parameterization by controlling rank collapse improves performance.
Citing
To cite this paper, please use the following reference:
@inproceedings{kumaragarwal2021implicit,
title={Implicit Under-Parameterization Inhibits Data-Efficient Deep Reinforcement Learning},
author={Kumar, Aviral and Agarwal, Rishabh and Ghosh, Dibya and Levine, Sergey},
booktitle={International Conference on Learning Representations},
year={2021}
}
Authors




For questions, please contact us at: rishabhagarwal@google.com, aviralk@berkeley.edu.